广义线性模型(GLM,Generalized Linear Model)
1 理论介绍
1.1 引言
当对数据进行回归分析时,经常会用到两类回归模型:
一类是针对连续型数据进行的线性回归,如下图(图片来源:维基百科)所示
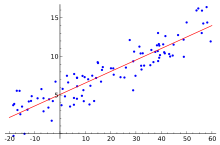
这种回归模型的公式是:
还有一类是针对分类数据进行的 logistic 回归,如下图(图片来源)
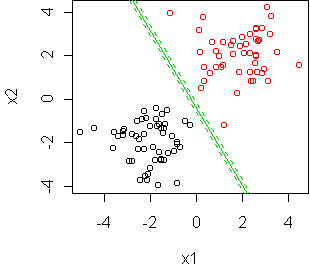
其中
是 sigmoid 函数,可以用来做二分类,其图像如下
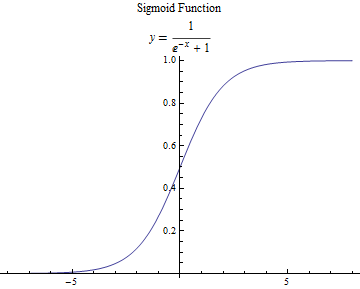
这两种回归模型,是否有可能统一到一种更加抽象的模型中?这两种形式完全不一样的模型,是不是只是某种更加广义的模型的特例?
1.2 广义线性模型的定义
Define 1 (广义线性模型(Generalized Linear Model),简称 GLM)
广义线性模型建立在三个定义的基础上,分别为:
- 定义线性预测算子
- 定义 y 的估计值
- 定义 y 的估值概率分布属于某种指数分布族
石老师可能有些看不懂?别着急,接下来详细解释各个定义
1.2.1 定义一 :线性预测算子
广义线性模型的名字中有『线性』两个字,自然它包含了线性计算的过程,也就是它的假设之一,定义线性预测算子(linear predictor)为:
这里的 和 都是向量,写成标量形式就是:
如果取 。可以发现和
是一样的,只是换了一下字母。
1.2.2 定义二:期望估计
先讲一下什么是估计,通常我们需要研究自变量 与因变量 的关系,这些数据可以通过做实验、爬虫获得。可以把通过给定的自变量 以及关于研究对象的参数 (可能是先验的,也可能需要通过研究得出)估计因变量 的过程,称为“估计”。
现有身高体重数据若干: 比如 (180,60),(190,70),(170,80),……
估计身高 200 的人体重是多少
已知身高 与体重 的关系满足以下分布
其中根据世卫组织 (自变量 ,参数 )
将 的期望作为对 y 的估计,即
所以估计身高 200 的人体重是 84 kg
将均值作为估计值是常见的,即
关于估计的理论,之后感兴趣再讲
1.2.3 定义三:指数分布族
可能你已经注意到了,在 example 1 里面,已知某分布
而满足分布
的,就满足广义线性分布。
显然 example 1 是满足的, ,线性预测算子 , ,
指数分布族的性质,见 指数分布族。